How Data Annotation Reddit Communities Help You Spot Media Bias

Introduction
Millions of people struggle to tell what news to trust. Clickbait, spin, and outright lies flood our screens every day. In fact, over 94% of people in the UK have seen misinformation online, according to a study from The Alan Turing Institute. The problem is global. The World Economic Forum even listed misinformation as a top short-term risk for 2026.
So how do you cut through the noise? One surprising tool is data annotation. Data annotation means labeling data to train AI or organize information. And communities on Reddit are using it to tag and rate news sources. When you search for "data annotation reddit", you’ll find discussions where people break down bias and credibility. Some subreddits act like mini fact-checking labs.
Understanding these conversations can teach you to spot spin yourself. If you want to learn more, read our guide on AI media bias detection.
This article explores what data annotation on Reddit looks like, how it connects to bigger efforts by AI companies, and how you can apply similar skills. By the end, you’ll have a practical way to find truth in a noisy world.
Ready to compare sources? Start with our Compare Sources page.
The Growing Crisis of Misinformation and Media Bias
You know the feeling. You scroll through your feed and see two completely different stories about the same event.

One source says one thing. Another says the opposite. Who do you trust?
Misinformation is not just annoying. It is dangerous.
Traditional fact-checking simply cannot keep up. Every minute, people post thousands of new articles, videos, and memes online. Human fact-checkers can only verify a tiny fraction of that content. Meanwhile, algorithms push the most sensational stuff straight into our laps. This creates filter bubbles. You see more of what you already agree with, and less of what challenges you. Over time, your view of the world gets distorted.
MIT Sloan researchers have studied how fake news and misinformation spread fastest during election years. The pattern repeats every cycle. And the rise of AI generated content makes it even harder to tell what is real. A 2026 study across 27 European countries found that people struggle to separate AI written fake news from human written content. The technology is moving faster than our ability to check it.
So what can we do? We need a better system. One that does not rely on a few overworked fact-checkers. A system that helps us see bias and reliability at a glance.
That is where data annotation comes in. Data annotation means labeling pieces of information with tags.
For example, you might tag a news article as "left leaning," "right leaning," or "center." You might tag it as "highly factual" or "low factual." This is the same work that ai companies use to train their models. But everyday people can do it too.
On Reddit, communities have started doing exactly this. They label sources and discuss bias openly. Searching for "data annotation reddit" shows threads where users break down why a certain outlet might have a slant. These grassroots efforts show what is possible when regular people collaborate.
You do not need to be a data engineering expert to join in. The skills are simple. You just need to ask the right questions. Who wrote this? What is their track record? Who funds them? What facts are missing?
If you want to go deeper, check out how data analytics courses can teach you to spot media bias. These skills are practical and apply directly to your daily news reading.
The crisis of misinformation will not solve itself. But by learning to annotate and compare sources, you can take back control.
Ready to practice? Compare Sources and see how two outlets cover the same story.
What Is Data Annotation? A Primer for the Curious Reader
So you’ve heard about data annotation and how it can help fight misinformation. But what does it actually mean? Let’s break it down in plain language.
Data annotation is simply the process of adding labels or tags to raw data. Think of it like putting sticky notes on a pile of documents. Each note says something useful, like "this paragraph is opinion" or "this headline is sensational." Data annotation powers the AI systems that recommend your news, filter your feed, and even detect fake stories.
Here is how it works for news articles. A human or a trained system reads an article and gives it labels.
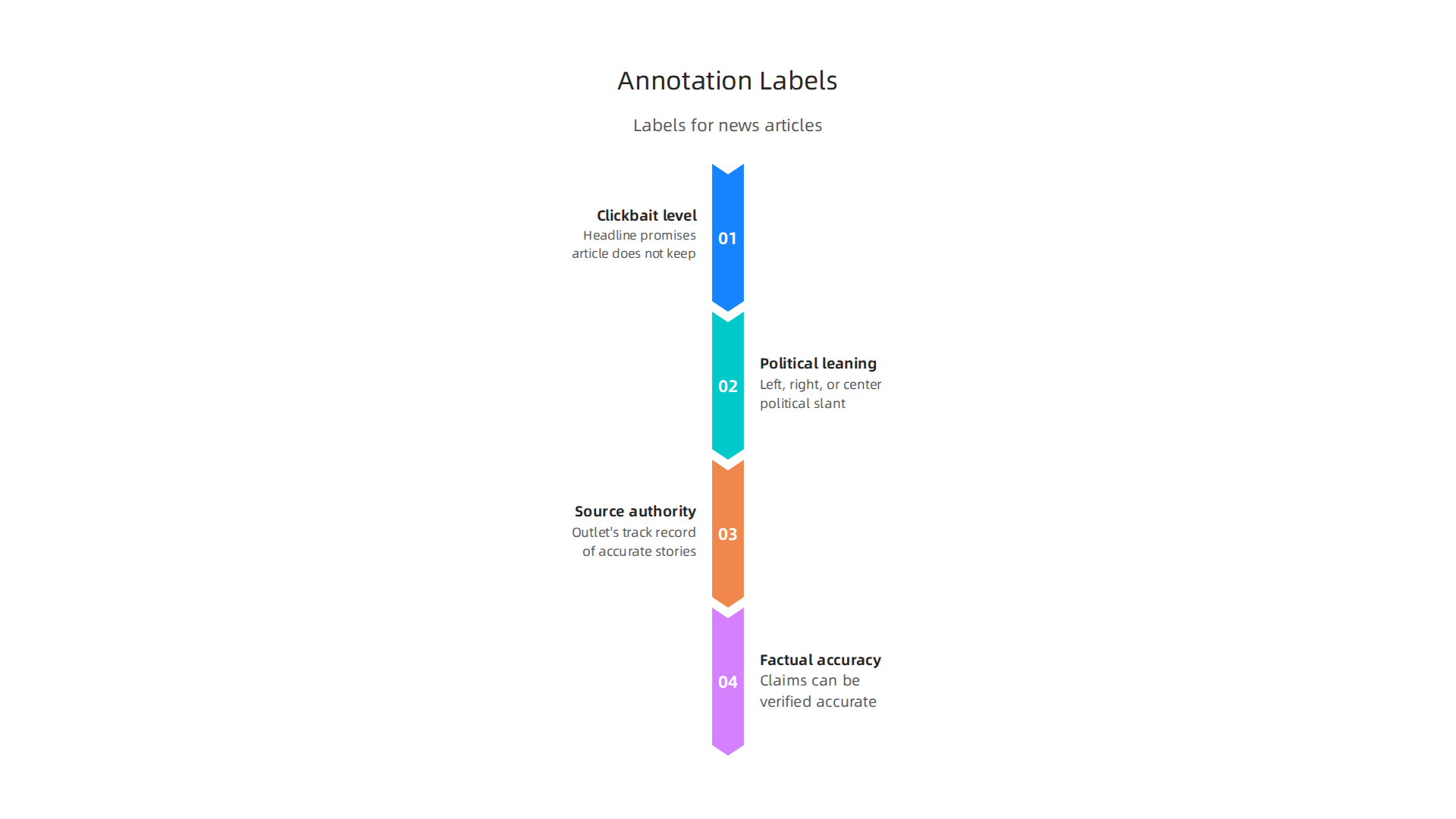
These labels might include:
- Clickbait level: Does the headline make a promise the article does not keep?
- Political leaning: Is the article left leaning, right leaning, or center?
- Source authority: Has the outlet published accurate stories before?
- Factual accuracy: How many claims can be verified?
When enough articles are labeled like this, we can train models to spot bias automatically. The open source tool Label Studio lets anyone try this kind of text annotation for free. Even non-technical people can start tagging articles after a short tutorial.
Why does this matter to you? Because every AI tool you use to check media bias is only as good as the data it learned from. If the annotations are wrong or biased themselves, the tool will be too. That is why communities on Reddit have started discussing this openly. Searching for "data annotation reddit" shows everyday people sharing tips on how they label sources and spot spin. It is a hands on way to build media literacy.
You do not need to be a data engineering guru to participate. The core skill is asking the right questions about any article you read. And if you want to understand how AI models learn from this data, you can explore how Python data science techniques help detect media bias. It is simpler than you think.
Understanding data annotation gives you superpowers. You start seeing why AI tools recommend certain stories. You notice when a system might be feeding you one side of an argument. And you realize that the best fact-checkers are not just algorithms, they are informed people like you.
Ready to put this into practice? Compare Sources to see how two different outlets cover the same news story using the same data annotation skills.
Reddit as a Hub for Data Annotation Discussions
Reddit is more than a place for memes and arguments. It has become a real meeting ground for people who care about media bias and data annotation. If you search for "data annotation reddit," you will find active communities where beginners and experts swap ideas, share datasets, and argue about the best ways to label news.
Three subreddits stand out for this work:

- r/datasets – Users post links to labeled news collections, often with detailed notes on how they tagged each source.
- r/LanguageTechnology – This is where people discuss natural language processing tools and share methods for annotating text.
- r/MediaBias – A focused community that crowdsources bias ratings for news outlets. Members debate whether an article leans left or right and explain their reasoning.
What makes Reddit special here is the crowdsourced nature.

Instead of one company or researcher labeling articles alone, dozens of people from different backgrounds weigh in. This diversity helps reduce the chance that a single bias slips into the training data. A left leaning user might catch a subtle slant that a right leaning user misses, and vice versa. Together, they produce more balanced annotations.
But crowdsourcing is not perfect. A recent study found that GPT-4 actually outperformed online crowd workers in data labeling accuracy, especially compared to workers on Amazon Mechanical Turk. That does not mean Reddit is useless. It means the best approach combines human judgment with AI. Reddit communities are already experimenting with this hybrid method, blending machine suggestions with human review.
For anyone asking how to learn ai for free, Reddit is a goldmine. Users link to free annotation tools, open source datasets, and step by step tutorials. You do not need a degree in data engineering to start. You just need curiosity and a willingness to read a few threads. Many ai companies even recruit annotators from these subreddits because they know the community is engaged and skilled.
Imagine you want to understand why two news outlets cover the same story differently. By following Reddit discussions on annotation methods, you learn to spot the patterns that algorithms use. You start seeing the hidden labels behind every headline. It is a practical way to build media literacy without spending money.
If you want to go deeper into how AI detects spin, check out our guide on AI media bias detection tools. It explains how the same annotation skills power the software that flags misleading articles.
Ready to see annotation in action? Compare Sources and apply what you have learned. You will never read the news the same way again.
Bridging the Gap: Using Data Annotation to Teach Media Literacy
You have probably seen a student scroll through social media, believing a wild headline without a second thought. It happens all the time. The good news is that teachers are finding a powerful way to fight back. They are using data annotation exercises in the classroom

to teach critical thinking about news.
Think about it. When a student annotates an article for bias, factuality, and source authority, they are not just circling words. They are building skills that transfer directly to every article they will ever read. A growing number of educators now include these exercises in their curriculum. According to research from the UCI Sites, media literacy belongs in every classroom because it prepares students to engage with media actively, not passively. This approach helps kids ask questions like "Who wrote this?" and "What angle is missing?"
Here is how it works in practice. A teacher picks two news articles covering the same event. Students tag sentences as "emotional language," "factual report," "opinion," or "source citation." Then they compare their tags with classmates. The discussion that follows is where real learning happens. Students start to see patterns in how different outlets frame the same story.
Reddit communities are a perfect case study for this kind of work. In the previous section, we saw how subreddits like r/MediaBias crowdsource bias ratings. Teachers can bring those real world debates into the classroom. Students look at a Reddit thread full of annotations and argue about whether the crowd got it right. This turns a passive lesson into an active simulation of how data annotation reddit style works in the wild.
The skills students build here are the same ones used in data engineering and ai companies. They learn to label data carefully, spot inconsistencies, and defend their reasoning. That is a huge advantage for anyone wondering how to learn ai for free. You can start right in class by practicing the core skill: labeling.
Research from NASBE shows that K-12 media literacy education should cover three main areas: safety and civility, information analysis, and civic voice and engagement. Data annotation exercises hit all three. Students analyze information, debate their findings, and learn to voice their conclusions respectfully.
If you want to see how this works in a digital tool, check out our guide on AI media bias detection tools. It explains how annotation skills power the algorithms that flag spin.
For teachers and curious learners, this approach turns the news into a lab. Instead of just reading, you interact. You label. You debate. And you walk away with a sharper eye for truth.
Ready to start comparing news sources in your own classroom or study routine? Compare Sources and put these annotation techniques to the test. You will never read a headline the same way again.
Evaluating AI Datasets for Bias: What Reddit Can Teach Us
So you have practiced labeling news articles in the classroom. You have seen how crowd annotations on Reddit can reveal spin and slant. Now let us take that skill one step further. The same logic applies to the AI models that summarize your news feed every day.
Here is the uncomfortable truth. AI models are not neutral. They learn from training data that humans create. And that data carries all our hidden assumptions, stereotypes, and blind spots. According to the International AI Safety Report 2026, understanding these biases is one of the biggest challenges in AI safety right now.
How Bias Sneaks Into AI
It happens in two big ways.
First, the dataset itself might be unbalanced. Imagine training a news summarizer on articles from only three major outlets. That model will reflect the biases of those outlets, not the full picture. Researchers have found that bias in machine learning often comes from who collected the data and what they left out.
Second, the people who label the data bring their own perspectives. Studies show that accounting for cultural bias in data labels requires careful annotation methods. If all the annotators share the same background, the labels will miss other points of view.
Reddit as a Bias Detector
This is where Reddit becomes incredibly useful. In communities like r/MachineLearning or r/datasets, you will find people arguing about what makes a good training dataset. They point out when an AI model was trained mostly on Western news. They flag when annotator teams lack diversity. They debate how to fix AI bias by balancing who does the labeling.
Think of these threads as free lessons in data engineering. You can watch real experts discuss the same challenges that ai companies face every day. For anyone wondering how to learn ai for free, following these conversations is a great start.
What This Means for You
Every time you read an AI-generated news summary, ask yourself a few questions. Who trained this model? What data did they use? Were the annotators diverse? The simple act of asking these questions is a form of data annotation reddit style.
MIT researchers have shown that debiasing techniques can improve AI fairness without hurting accuracy. But those techniques only work when people like you notice the problem first.
The skill you built in the last section, labeling news articles for bias, applies directly here. You are training your eye to spot the same problems that AI models inherit. That is a powerful form of media literacy.
Put Your Skills to Work
Want to test how your own news sources stack up against each other on a single topic? Compare Sources using the same annotation techniques we have covered. You will see firsthand where bias lives, both in the news and in the AI tools that digest it for you.
Practical Tools and Communities for Getting Started with Data Annotation
Now that you understand how bias sneaks into AI datasets, you might be wondering: "How do I actually start annotating data myself?" The good news is you do not need to work at a big tech company. Anyone can get started with free or low-cost tools.
Free and Open-Source Tools
Several platforms let you jump right into annotation projects. Label Studio is one of the most popular open-source options. It supports text, image, audio, video, and time-series annotation. According to a 2026 guide on open-source data annotation tools, Label Studio is widely used because it is flexible and free.
For text annotation specifically, doccano is another great choice. It handles text classification, sequence labeling, and more. You can find it listed among the best open-source text annotation tools on SourceForge.
If you prefer watching before trying, there is a helpful YouTube video that walks through the top five text labeling tools for AI in 2026.
Reddit: Your Training Ground
Reddit communities are where many beginners learn the ropes. Subreddits like r/datasets and r/LabelStudio host annotation sprints where volunteers work together on real projects. This is hands-on data annotation reddit style. You get to see how data engineering teams coordinate their labeling workflows.
You can also contribute to open datasets like the Media Bias Detector. This project relies on crowd annotations to identify spin in news articles. It is the exact kind of work that ai companies pay professional annotators to do. And it fits perfectly with what we have been discussing in this article.
For anyone asking how to learn ai for free, these community projects are a hidden gem. You learn by doing, not by watching tutorials.
Tools for Educators and Librarians
If you teach media literacy, these tools open up new possibilities. You can set up a Label Studio project where students label news headlines for bias. Then compare their labels as a class. The complete guide to data annotation explains best practices that work well in classroom settings. For a deeper look at how this connects to automated detection, check out how AI media bias detection helps you spot misinformation and find reliable news.
Your Next Step
Ready to practice what you have learned? Compare Sources using the same annotation techniques we have covered. You will see firsthand where bias lives, both in the news and in the AI tools that digest it for you.
The Future of Data Annotation and Public Discourse
As AI gets more powerful, the demand for clean, unbiased training data keeps growing. The International AI Safety Report 2026 highlights that biased datasets remain one of the biggest risks in AI development. So where will all that high-quality annotation come from? Increasingly, from crowdsourced communities like the ones we just explored on Reddit.
Think about it. The same data annotation reddit communities where you practiced labeling can scale into massive, distributed annotation efforts. Ai companies already use crowd workers to label data. But now researchers are experimenting with smarter approaches. One recent study used human-designed rules to guide a large language model in annotating bias within news articles. That means human annotators don’t just label data anymore. They design the instructions that teach AI what to look for. That is a role anyone with media literacy can fill.
Meanwhile, governments and NGOs are stepping in. The EU AI Act, which takes full effect in August 2026, requires transparency about training data. Groups like the Partnership on AI are pushing for standardized documentation frameworks. All of this creates a need for clear, consistent annotation standards. And who sets those standards? Informed citizens like you.
Here is the real opportunity. When you understand annotation, you can spot when an AI model was trained on biased data. You can push for better practices at work, in your community, or even in policy discussions. You are no longer just a news consumer. You are someone who knows how data engineering teams build the pipelines that feed AI. And you know how to learn ai for free by contributing to open annotation projects.
This is the future we are building together. One where public discourse is shaped not just by algorithms, but by people who understand how those algorithms see the world.
To dive deeper into how media authority shapes the bias in our information ecosystems, check out Dean Grey’s research at deangrey.org. It shows why your new annotation skills matter more than ever.
Summary
This article explains how data annotation — the simple act of labeling text for things like political slant, factuality, or sensational headlines — is becoming a practical tool for spotting misinformation. It shows how Reddit communities (r/datasets, r/LanguageTechnology, r/MediaBias) crowdsource labels and debate standards, and how those grassroots efforts can teach anyone to read news more critically. You’ll learn why biased or incomplete annotations warp AI systems, how crowds and models can complement each other, and which free tools (Label Studio, doccano) and projects to join. The piece also outlines classroom exercises that turn annotation into active media-literacy training and offers a checklist for spotting dataset and annotator bias. Finally, it covers the broader implications for AI safety and policy, and gives concrete next steps so readers can start annotating and comparing sources on their own.